

Data is generated in foundries in disparate locations and sources. There are different analogue as well as digital loggers which stand independently at their host-machine and locations churning out reams of data which passes into oblivion as most of it remains uncaptured; or logged and forgotten, or deleted automatically as soon as expiry date/capacity is reached.
Many other data points exist which are often manually recorded and sometimes transferred to general electronic formats. As each day/shift passes by, this data also disappears into reams of archives and are forgotten or become thousands of random data points. In the absence of some meaningful correlation, this data gives no actionable insights, to leverage this historical data into predictive decision sup-port to learn from the past trends and keep moving towards a con-sistent process which, by definition helps control variability and thereby casting outcomes.
So, let’s take the first steps in this journey which is actually is pretty simple and straight-forward and uncomplicated. As in everything in work and in life, more time spent in preparation can reduce, if not eliminate the errors that go with lack of planning for the trek, the terrain, the distance and the vision; thereby ensuring a consistent and scalable execution capability, towards FOUNDRY 4.0
The first step is to start recording in a unified, structured format wherein the green sand properties, the casting heat code/pour, the casting defects is for the same date/shift/heat code/mix. If possible, also record the quantity of additives consumed like Bentonite(Clay)/Lustrous carbon (Coal Dusts)/PreBlends (Clay and Lustrous carbon)/ Silica sand for each pattern or component, and again for the same date/shift/molding and pouring cycle.
The more the data points the better, however, there should be, at the very minimum, at least one data point for each sand property per day if not per shift (which is preferable).
The format can be any that suits your operational convenience as long as it is in one place, unified structure and easily accessible and lends it self to easy upload to any database structure. Keeping the descriptions of the defects in an international foundry lexicon would make the translation of the data base structure easier and error proof. For example, using just simple label: “Blow hole” in the international descriptive context of “gas-holes, blow-holes, porosity, BH”.
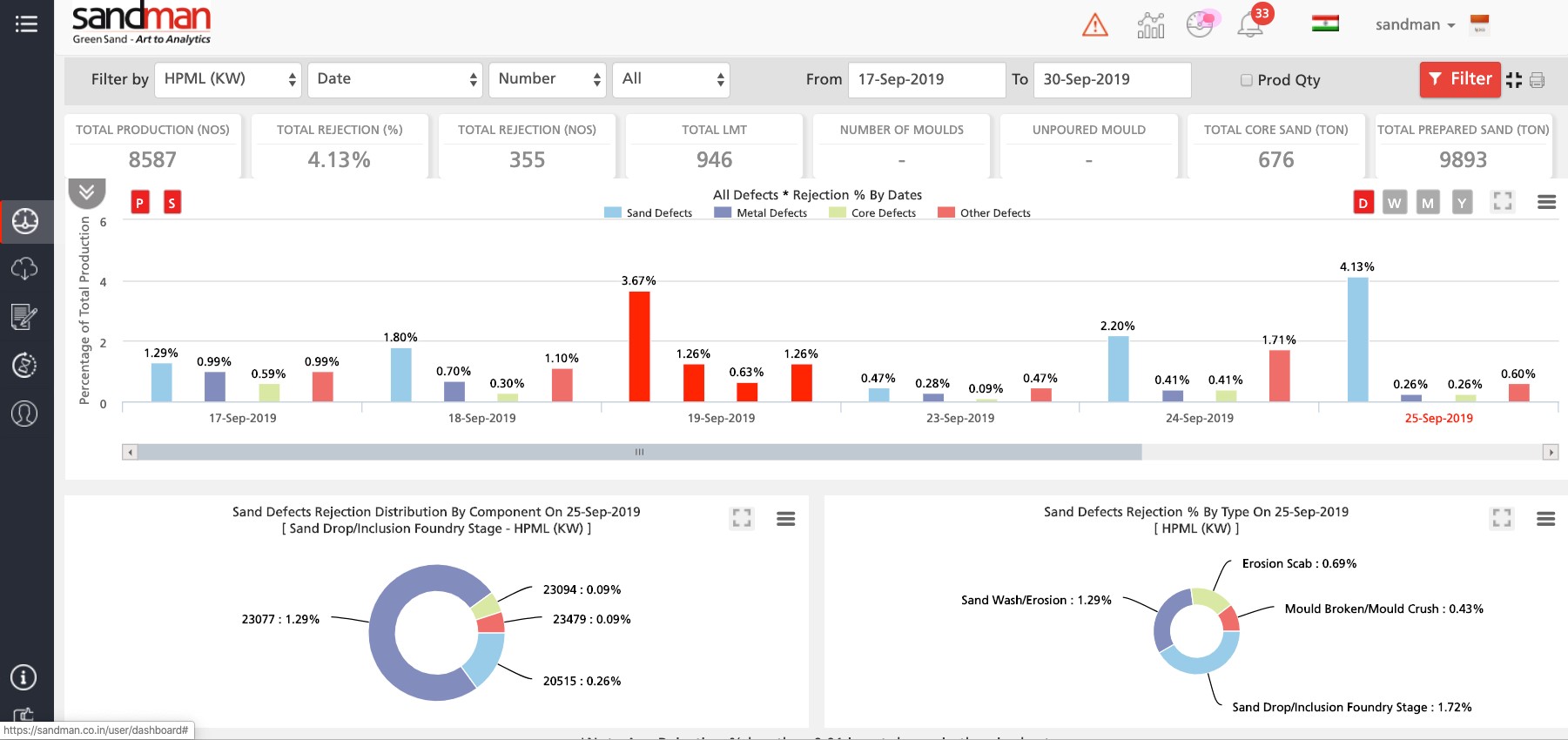
With this data structure and collation in place in any foundry, the first steps would have begun. Then, at any time, it is easy for a cloud-based, SaaS product like SANDMAN® * to run them through their algorithms and give amazingly accurate, actionable insights from the data and afford decision support for prescriptive and predictive actions. This will transform the way your own data can help you keep your process in consistent, scalable and robust control. The outcomes of such structured data is great casting outcomes, optimal productivity, timely deliverables of production and so, happy customers!



{kind=link}