
Author: Deepak Chowdhary – Inventor of SANDMAN data analytics SaaS software for green sand molding and digitalization in foundries.
Data Science is precisely what the name suggests: it is the science of mathematically modeling data and using the logic and computational flow of algorithms to predict outcomes and recommend the most optimal solutions to achieve them in the process to which applied.
In Machine Learning (ML), the historical and real-time data that is determined for modeling is processed and analyzed to derive an optimal solution. Typically, the data source applied is a human decision. ML cannot decide which data is relevant or access data on its own decision to target the desired outcome. Therefore, the accuracy of data modeling has its own perceptional limitation in "data-driven decision" making.
True AI may be able to impute data beyond what is available or seen in the data sets using advanced technologies like used in autonomous cars, for example. Someday, maybe sooner than later, casting processes will be AI-driven. But first, at this juncture in moving towards Industry 4.0; foundries still have a lot to catch-up on the concepts and tremendous value of digitalization and machine-learning decision support for-profits in terms of; reduced casting rejections, dose-by-need additive consumption and the often overlooked but considerable savings in time (time also being money) in analyzing unexpected shop-floor problems and process deviations, and being alerted to them well in time.
Data by itself is just a set of figures or numbers. By itself and without correlation, there is not much one can do or make out of the data sets. In other words, data without insight is meaningless data: Example:
Data visualization - without correlation
Insight is just the first goal of data modeling. Actionable insight is the next goal. When data can guide and or predict an action, then that is meaningful data.
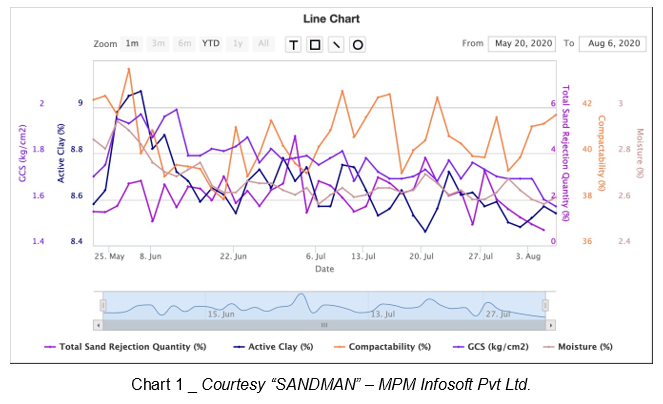
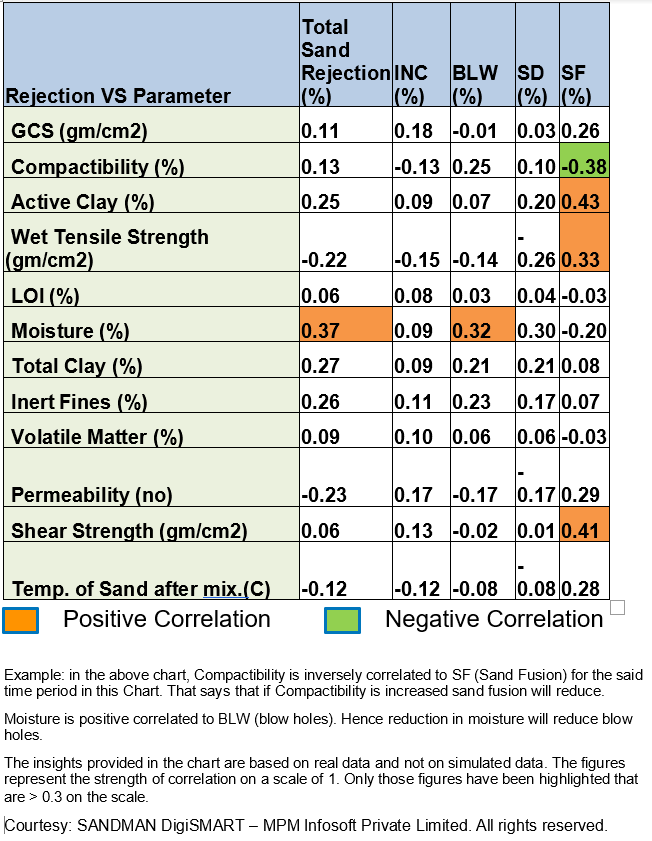
For example, in foundry green sand molding processes, if we just know that from the correlation of all the available sand properties in a foundry, active Clay is influencing defects the most in a given date and time series, that's an insight. Now, if the analytics can provide some directional prediction support in terms of increasing or decreasing the active Clay to achieve better outcomes in terms of defect reduction, it's a more actionable insight and, therefore, more meaningful. Now that cold data set has value!
However, the real value of data analytics support comes into play when the algorithm is able to predict and prescribe near-precisely how much of an increase/decrease in the active clay percentage is optimal to achieve related casting defect reduction.
An analytic data software can either be generic or specific for a process or domain, be it in manufacturing, services, whether physical, virtual, or internet delivered.
If the algorithm is generic, it can only create co-relation between data sets and predictions arising therefrom without the benefit of specific domain know-how. Therefore, without specific or granular and domain enriched insights on the relevancy of the modelled data-set, it is difficult to expect to achieve specifically targeted casting outcomes.
On the other spectrum, some algorithms are built around specialized domain inputs wherein the causal co-relations are modeled from the infusion of know-how and experience of skilled domain experts. That is where algorithms are designed and embedded with 'virtual artificial intelligence.' The predictions from algorithms deriving from the know-how and logic of trained, skilled, and domain-focused expert minds enable better and more accurate casting and process control outcomes.
However, despite the actionable insights derived from predictive and prescriptive models, the continuously evolving and dynamically changing conditions in foundry eco-systems such as varying core sand influx, will keep pushing the needle away from the goalpost. The model predictions will, at the same time, keep the process equally dynamically targeted towards the goal post.
"This dynamic "push and pull' is where the perspective of data science as a "decision support" needs to be understood. User expectations driven by calculating ROI solely in terms of liquidated profits deprive the user of the sight of the benefits that the data-driven process control is providing, many a time intangibly."
Constant, Consistent, Accurate, and Scalable control of the entire molding process, based on digitalization of data using sensors (IIoT), SCADA, and even manual laboratory sources, is the real ROI.
Algorithms will work whenever the process accesses them. However, the availability of continuous, correlated, collated, and authenticated data without gaps in dates and time is the key for the software to do its job.
In dynamic conditions, when the results need review, the following common and few examples of common reactions need thought-leadership review. Here are some Frequent Reactive Responses:
- Reaction: "There is no change in the casting eco-system"
- Translation: there is no change in the sand to metal ratios. No change in the thermal load due to changed production schedules, no change in additive dosages, are some examples
- Review: have we thoroughly analyzed the thermal loading change due to pattern changes and scheduling? can we log additive dosing and thermal loading data based on sand: metal ratios, line speed and thereby improve consistency of the sand for better casting outcomes?
- Reaction: "No change in core influx."
- Translation: Patterns loaded are the same. There are no changes in patterns having varying core to metal ratio.
- Review: Maybe the patterns are the same. However, is there any increase in the high cored jobs over the low/non-cored jobs? Is there a change in not only the type of pattern but also the quantity produced per pattern? Can we use data to monitor the impact of these changes?
- Reaction: "The software predictions cannot be followed."
- Translation: our machines cannot change in the dosage graduations required or, we do not have weighing systems to measure additive dosages.
- Review: Do we now need to upgrade our machines and processes to match modern data-based control processes? Can we have dose-by-need data-based decision support on additives?
- "Reaction: We have always done the process in a certain way."
- Translation: Change of process conditions and norms is not possible.
- Review: Should we start looking at the possibilities to do things in a different way, given that we have new data sources, more resources, increased ability to train human resources, so that we can achieve what seems impossible at the moment?
The takeaway on the perspective of driving process improvement for optimal (casting) outcomes is to treat the software as a quasi-expert, always on the job 24/7, guiding the process with an accuracy even the best experts cannot engage in or achieve on a real-time basis.
However, the foundry line manager/s and expert/s still need to keep an experienced eye open to monitor whenever a process seems counter-intuitive. Even here, a system of alerts keeps the process owner aware, automatically.
When results are not what is expected, it is important to put in perspective that the algorithms are still modelling the data accurately. It just maybe that the logic and computational flow needs to be further refined with newer or additional data inputs, sources and co-relations. Or, there could be a system over-ride due to perceptional domain-based reasons of the process owner. A healthy feedback and annotation system can lead to co-enrichment of the software with the customer to make it more intuitive, intelligent, responsive and accurate-to-purpose.
With an objective perspective; analytics-based ROI is a true win-win for all stakeholders: the user, the developer, and the Industry.






{kind=link}
{kind=link}
{kind=link}